HTPP协议的Expext 100-continue导致的“操作超时”
莫名其妙的“操作超时”
在用C#的HttpWebRequest写一个HTTP客户端请求时,遇到了一个莫名其妙的问题,就是在发送POST请求时,总是报“操作超时”的错误。核心代码如下:
1 | ... |
在执行bRequest.GetResponse()时会卡住,一直等待直到报“操作超时”的错误。
分析与排查
代码问题的几率很小
这段代码没啥好说的,是老系统里千锤百炼留下来的基础代码。从网络上找到的教程什么的,大致也是这样写的,所以代码的问题的几率很小。
也不是服务端处理慢
服务端的响应不涉及复杂的业务处理,这个可以直接排除。
用Postman测试可以正常访问
用Postman测试,没有出现“操作超时”的错误。这个问题就很奇怪了,Postman的请求和代码里的请求应该是一样的,为什么Postman可以正常访问,而代码里就不行呢?
用Fiddler抓包分析
只有用Fiddler抓包分析,来看看代码的request跟Postman的请求有什么差异。发现代码里的请求,主要差异是多了一个Expect: 100-continue的Header。
Postman复现问题
Postman加上100-continue的Header,就可以复现“操作超时”的问题。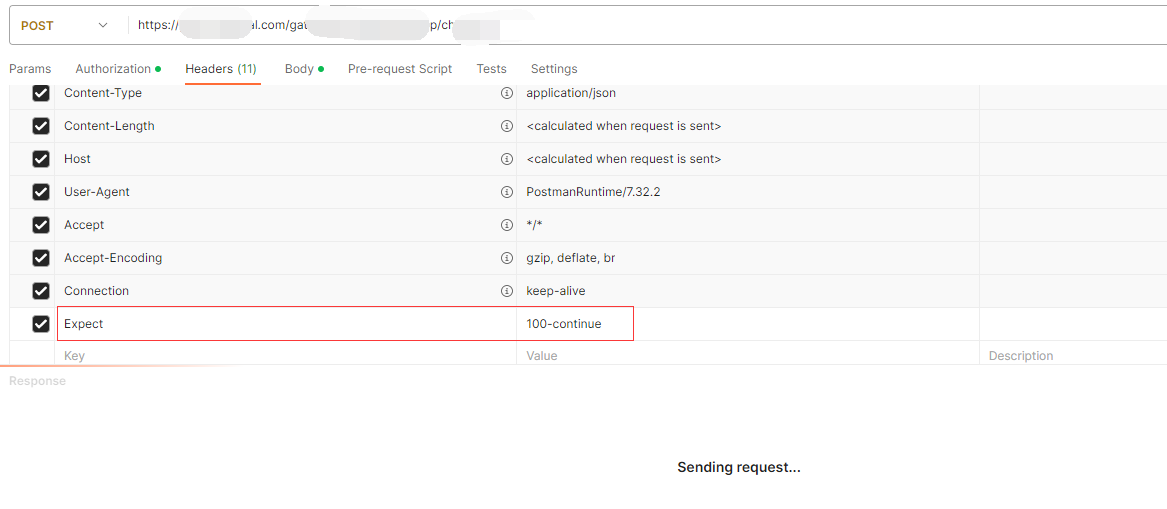
罪魁祸首之100-continue
查了一下资料,100-continue是HTTP 1.1里设计的一个状态码,在发送请求体之前,先发送一个Expect: 100-continue,如果服务器响应了100-continue,那么就会继续发送请求体。
这个设计的目的是为了在发送大量数据时,先确认服务器是否接受这个请求,如果不接受,就不用发送大量的数据了,从而减少网络带宽的浪费。
这就跟本文的问题对上了,刚好是带请求体的POST请求,所以先发送Expect: 100-continue,但是服务器没有响应100-continue,就一直等待到“操作超时”。
解决方案
定位到具体的原因后,解决起来就容易了,有两种方案(任选其一):
客户端:禁用100-continue
1 | wbRequest.ServicePoint.Expect100Continue = false; |
服务端:支持100-continue或者忽略100-continue
这个得看服务端的网关是什么了,可以配置为HTTP协议为1.1,或者把请求头里的Expect: 100-continue过滤掉。