官方文档JobRunr Doc
安装
在Spring Boot上的安装非常简单,有Spring Boot Starter
Spring boot 2的Maven依赖包:
Spring Boot 2 1 2 3 4 5 <dependency > <groupId > org.jobrunr</groupId > <artifactId > jobrunr-spring-boot-starter</artifactId > <version > 5.1.3</version > </dependency >
JobRunr从6.0开始支持Spring Boot 3:
Spring Boot 2 1 2 3 4 5 <dependency > <groupId > org.jobrunr</groupId > <artifactId > jobrunr-spring-boot-3-starter</artifactId > <version > 6.1.3</version > </dependency >
配置application.yml,主要是开启/关闭 JobRunr 的Server和Dashboard,Server用来执行job,Dashboard则是在一个独立的端口提供网页看板:
1 2 3 4 5 6 7 8 9 10 org: jobrunr: background-job-server: enabled: true dashboard: enabled: true port: 8000 database: skip-create: false
使用JobScheduler创建Job 1 2 3 4 5 6 7 8 9 10 @Autowired private JobScheduler jobScheduler;... SomeTask task = ...jobScheduler.enqueue(UUID.fromString(task.getId()), () -> { someService.someMethod(task); });
使用注解创建重复执行的任务(Job) 1 2 3 4 5 6 7 8 9 10 11 12 @Recurring(id = "per-day-trigger-job", cron = "0 0 7 * * *") @Job(name = "每天的7时触发") public void bizMsgPerDayTrigger () { ... } @Recurring(id = "per-minute-trigger-job", interval = "PT1M") @Job(name = "每分钟触发") public void bizMsgPerMinuteTrigger () { ... }
Dashboard Dashboard是一个网页看板,在这里可以查看任务的执行情况,也可以手动触发任务、删除任务。
个人觉得选用JobRunr,一方面是与Spring Boot集成比较方便,这样在开发和运维上比较节省人力和服务器资源,当然这可能是个双刃剑,对那些不差钱也不差人的场景来说,这是“缺点”;另一方面是Dashboard的可视化,会增加我们的掌控感。
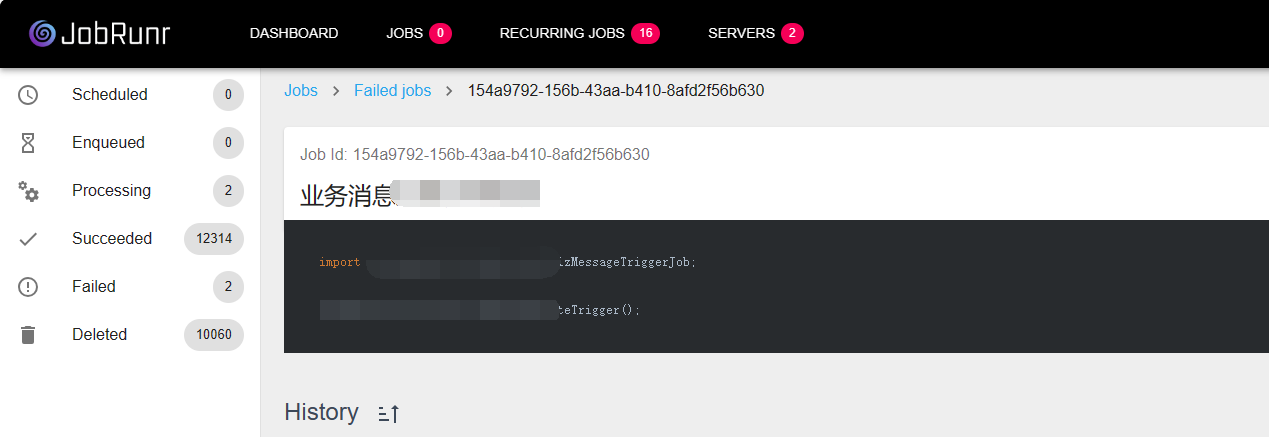
有问题的Job会进入Scheduled状态 JobRunr建议在写Job的执行代码时,把异常抛出来,这样JobRunr就会把这个Job的状态设置为Failed,然后在Dashboard上可以看到这个Job的执行情况,如下图所示:
如果某个Job每次执行都抛异常,就会进入Scheduled状态,以更低的频率执行。
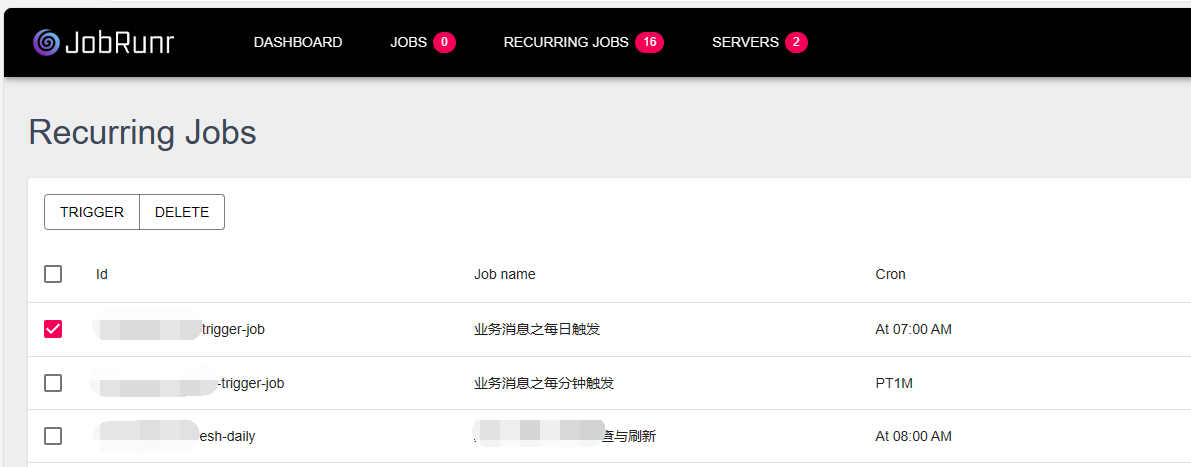
重复执行任务的手工触发和删除 有些任务,比如每天甚至每周才执行一次,如果想手工触发,可以在Dashboard上的RecurringJobs下,勾选Job,然后点击“Trigger”按钮触发,如下图所示:
任务的删除,主要是这种场景:代码做了修改之后,使用@Recurring和@Job注解申明的任务,名称变了或者不需要了,也就是代码里其实已经没有这个名称的Job了。这时候可以在Dashboard上的RecurringJobs下,勾选Job,然后点击“Delete”按钮删除。